Go GMP调度器的设计与原理 |
您所在的位置:网站首页 › golang gmp模型中g阻塞 › Go GMP调度器的设计与原理 |
Go GMP调度器的设计与原理
|
1. 简介#
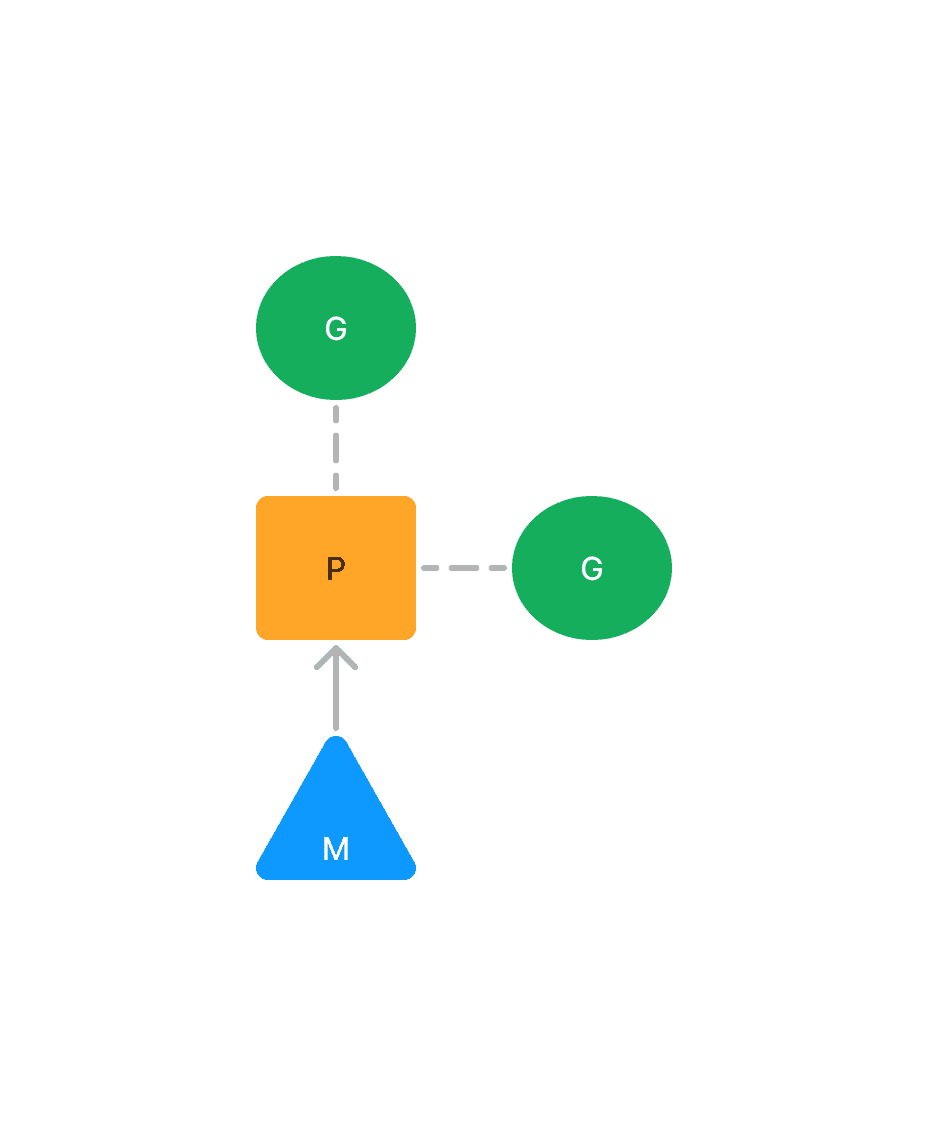
Go 具有强大的兵法能力,可以通过 go 关键字创建大量的协程(goroutine),帮助程序快速执行各种任务。而协程的调度是通过 GMP调度器来控制和调度的。 1.1 协程#在计算机系统中,进程是应用程序的启动实例,每个进程都有独立的内存空间,不同进程通过进程间通信方式来相互通信。而线程则是从属于进程,每个进程包含一到多个线程,线程是 CPU 调度的基本单位,由操作系统控制调度,多个线程之间可以通过共享内存的方式来相互通信。 而协程则可以理解为一种轻量级的线程,协程不受操作系统调度,而是由应用程序提供调度器,按照调度策略把协程调度到线程中去运行,从操作系统看来则是一个线程在执行中的黑盒行为。当多个线程在并发调用时,系统上下文切换开销将会变大,而协程间的切换是在用户态进行的,可以大大减少上下文切换的开销。线程的内存占用是 MB 级别,而协程的内存占用仅是 KB 级别,初始化为 8KB,最大可扩张至 1GB,内存消耗远比线程要小。 Go 原生支持协程,在 Go 中的协程称为 goroutine,使用 go 关键字即可创建协程。 1.2 GMP调度器#Go 使用 GMP调度器对协程进行调度,将它们分配至 CPU 上去执行。GMP调度器的三个核心概念分别为 G、M、P。 G 指的是 goroutine,也就是协程,也可以看做是待执行的任务。每个 goroutine 都有自己独立的栈存放当前的运行内存及状态,在被 CPU 调度和结束调度时,会将 CPU 寄存器的值读取和写回 G 结构体中的对应成员变量。 M 指的是 machine,等同于操作系统中的线程,由操作系统的调度器进行调度和管理。每个工作线程都有唯一的一个 M 结构体的实例对象与之对应,M 结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的Goroutine 以及是否空闲等等状态信息之外,还通过指针维持着与 P 结构体的实例对象之间的绑定关系。 P 指的是 processor,表示一个虚拟的处理器,可以把它看作在线程上运行的本地调度器,它代表 M 运行 G 所需要的资源,这里并不指代 CPU。P 的数量默认值等于 CPU 的核心数,但可以通过环境变量 GOMAXPROCS 修改。每个 G 要想真正运行起来,首先需要被分配一个 P,然后这个 P 还需要绑定到一个 M 上。
GMP调度器就是运行时在用户态提供的多个函数组成的一种机制,目的是高效地调度 G 到 M 上去执行。 2. 调度模型的设计思想与演进# 2.1 传统多线程#在现代操作系统中,为了提高并发处理任务的能力,一个 CPU 通常会运行多个线程,由操作系统通过调度器对多个线程进行创建、切换、销毁,这些操作的开销通常比较大。在高并发的情况下,大量线程的创建、切换、销毁会占用大量内存,浪费较多的 CPU 时间在非工作任务的执行上,对程序并发处理事物的能力造成影响。用户创建的线程和系统线程是 1:1 的关系。 一个内核线程的大小通常达到 1M,需要分配内存来存放用户栈和内核栈的数据 在一个线程执行系统调用,如发生网络请求或文件读写时,不占用 CPU,需要及时让出 CPU 给其他线程执行,会发生线程间的切换 线程在 CPU 上进行切换时,需要保持当前线程的上下文,将待执行的线程上下文恢复到寄存器,需要向操作系统内核申请资源,以及发生内核态和用户态的切换
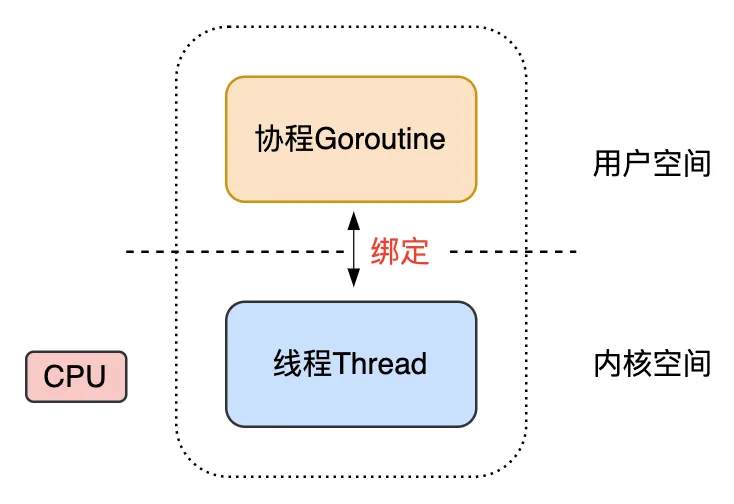
在 Go 的早期版本,将线程分为了两层概念:线程 M(machine)和协程 G(goroutine),它们分别处于内核空间和用户空间。 M 是内核线程,是操作系统控制 CPU 调度的基本单元。 G 是轻量级用户态的协程,代表了一段需要被执行的代码的封装,每个 G 都有自己独立的栈存放程序的运行状态,初始分配内存大小仅为 2KB,并且可以按需扩缩容,最大可以去到 1GB。
在早期的调度器,一个 Go 程序只有一个 M 线程。在将传统线程拆分为 M 和 G 之后,为了充分利用轻量级协程 G 的低内存占用和低切换开销的优点,会在当前的 M 上绑定多个 G,当前运行中的 G 执行完成后,调度器就将当前 G 切换,并将其他可以运行的 G 放入 M 去执行。用户创建的协程和系统线程是 N:1 的关系。 这个方案的优点是用户态的 G 可以快速低成本地切换,不会陷入内核态。缺点是无法充分利用多核 CPU 的硬件能力,且 G 阻塞会导致与其绑定的 M 阻塞,其它 G 也无法执行。
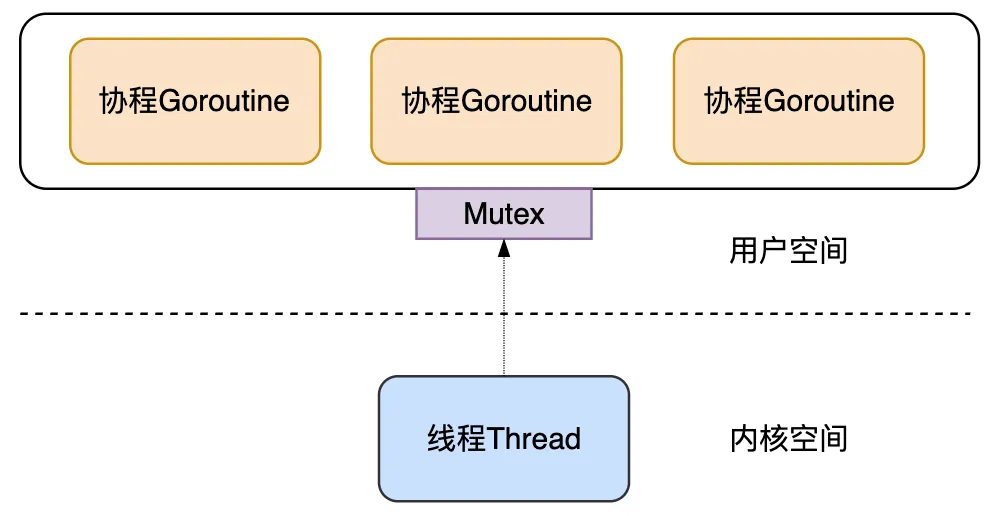
为了解决这些不足,Go 后来发展成了多线程调度器。 在新的调度器中,有多个 M 对应多个 G,利用了多核 CPU 提升并发处理能力。但这个方案也有缺点: 全局锁和中心化状态带来锁竞争,导致性能下降 每个 M 都能执行任意可执行状态的 G,M 频繁地和 G 交接,导致额外开销 每个 M 都需要处理内存缓存,导致大量内存占用,并影响数据局部性 系统调用频繁阻塞和解除阻塞线程,增加了额外开销
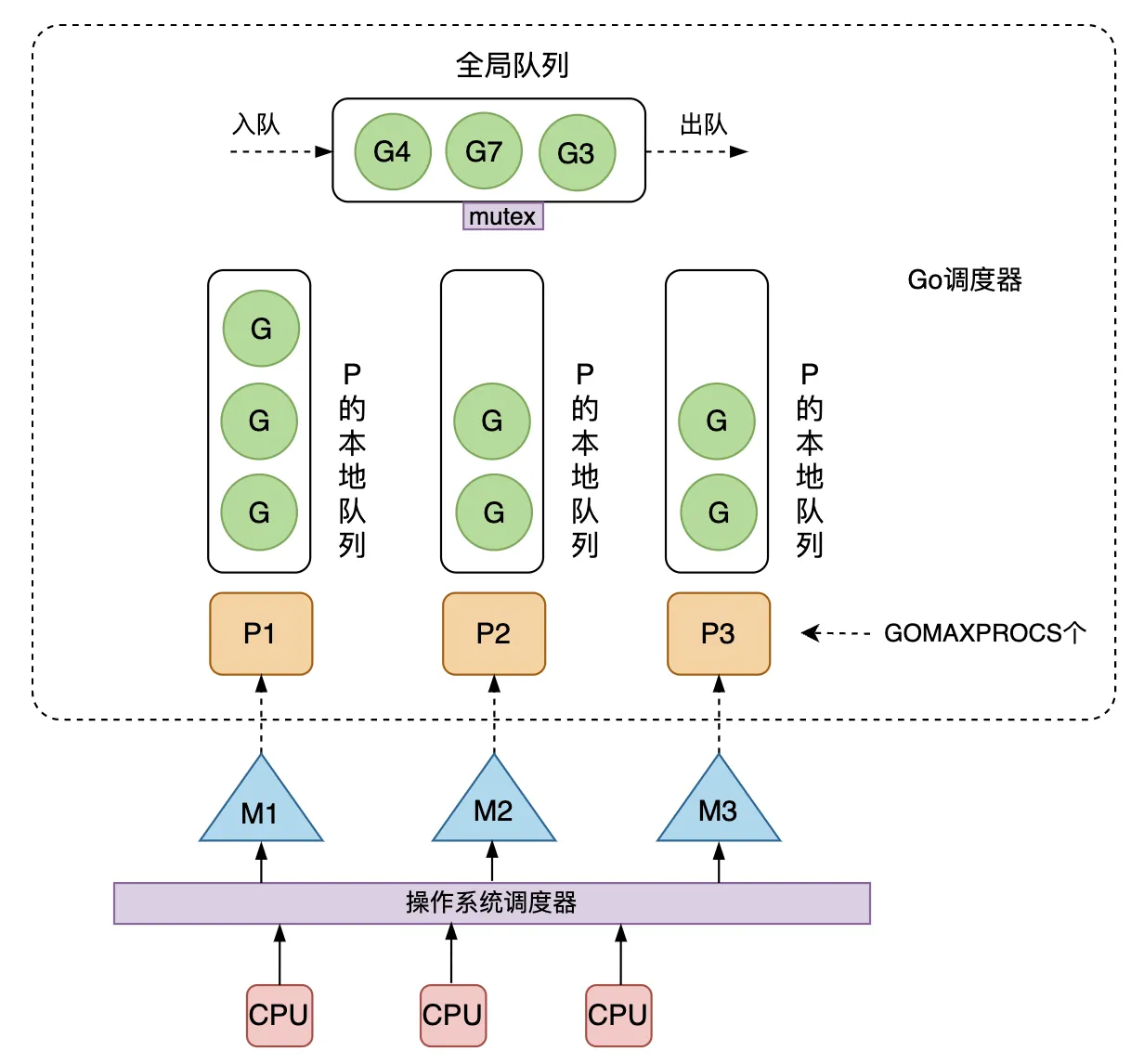
为了解决多线程调度器的问题,Go 在已有的G、M基础上,引入了P(processor),构建了目前的 GMP 调度模型。用户创建的协程和系统线程是 M:N 的关系。 P 代表了一个虚拟的处理器,它维护一个局部可运行的 G 的队列,可以通过 CAS 的方式无锁访问。每个 G 想要运行起来,需要被分配到一个 P。工作线程 M 会优先使用自己的局部运行队列中的 G,只在必要时才会访问全局运行队列,大大减少了锁冲突,提高了大量 G 的并发性。 下图就是 GMP模型的整体架构。可运行的协程 G 是通过处理器 P 和线程 M 绑定起来的,GMP 调度器负责调度 G 到 M 上去执行,主要在用户态运行。而 M 的执行是由操作系统的调度器将线程分配到 CPU 上实现的,在内核态运行。 在操作系统看来,运行在用户态的 Go 程序只是一个请求和运行多个线程 M 的普通进程,操作系统并不会直接跟上层的 G 打交道。 之所以不直接将 P 的本地队列放到 M 上,而是要放到 P 上,是为了在某个线程 M 阻塞时,可以将和它绑定的 P 上的 G 转移到其它线程 M 去执行。如果 G 时直接绑定到 M 上的,那么当 M 阻塞时,它拥有的 G 就无法转移到其它 M 去执行了。
GMP模型有以下几点核心思想: 尽可能服用线程 M:避免频繁的线程创建和销毁; 利用多核并行能力:限制同时运行的 M 线程数,数量一般等于 CPU 核心的数量,这个数量可以通过设置 GOMAXPROCS 来指定。没有找到 P 的 M 会放入空闲 M 列表,没有找到 M 的 P 也会放入空闲 P 列表; Work Stealing 任务窃取机制:M 优先执行绑定的 P 上的本地队列中的 G,如果本地队列为空,则从全局队列中获取 G,也可以从其它 M 偷取 G 来运行; Hand Off 交接机制:当 M 阻塞时,会将 M 上的 P 的运行队列交给其它 M 执行; 基于协作的抢占机制:每个 G 运行 10ms 就要让出 M,交给其它 G 去运行,防止新创建的 G 一直获取不到 M 执行造成姐的问题; 基于信号的真抢占机制:Go 1.14 引入了基于信号的抢占式调度机制,能够解决 GC 垃圾回收和栈扫描时存在的问题;下面我们来看下,一次 go func() 语句创建一个协程并执行,所经历的调度流程。
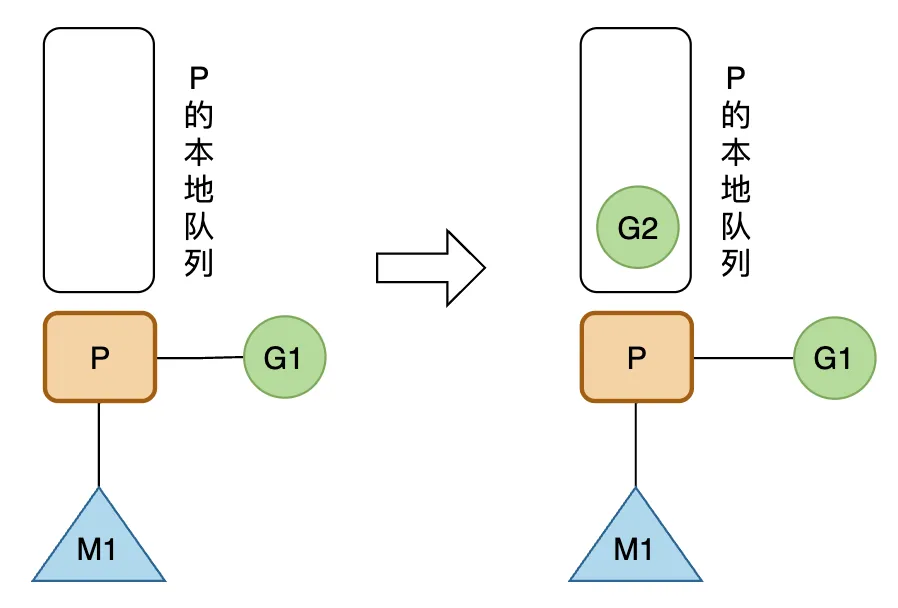
下面通过几张图片描述一下 GMP 调度器的一些调度场景,更直观地展示 GMP 是如何保证公平性和可扩展性,提高并发效率,以及一些机制和策略。 3.1 创建G#正在 M1 上运行的 P,有一个 G1。通过 go func() 创建 G2 后,为了局部性,G2 会被优先放入 P 的本地队列。
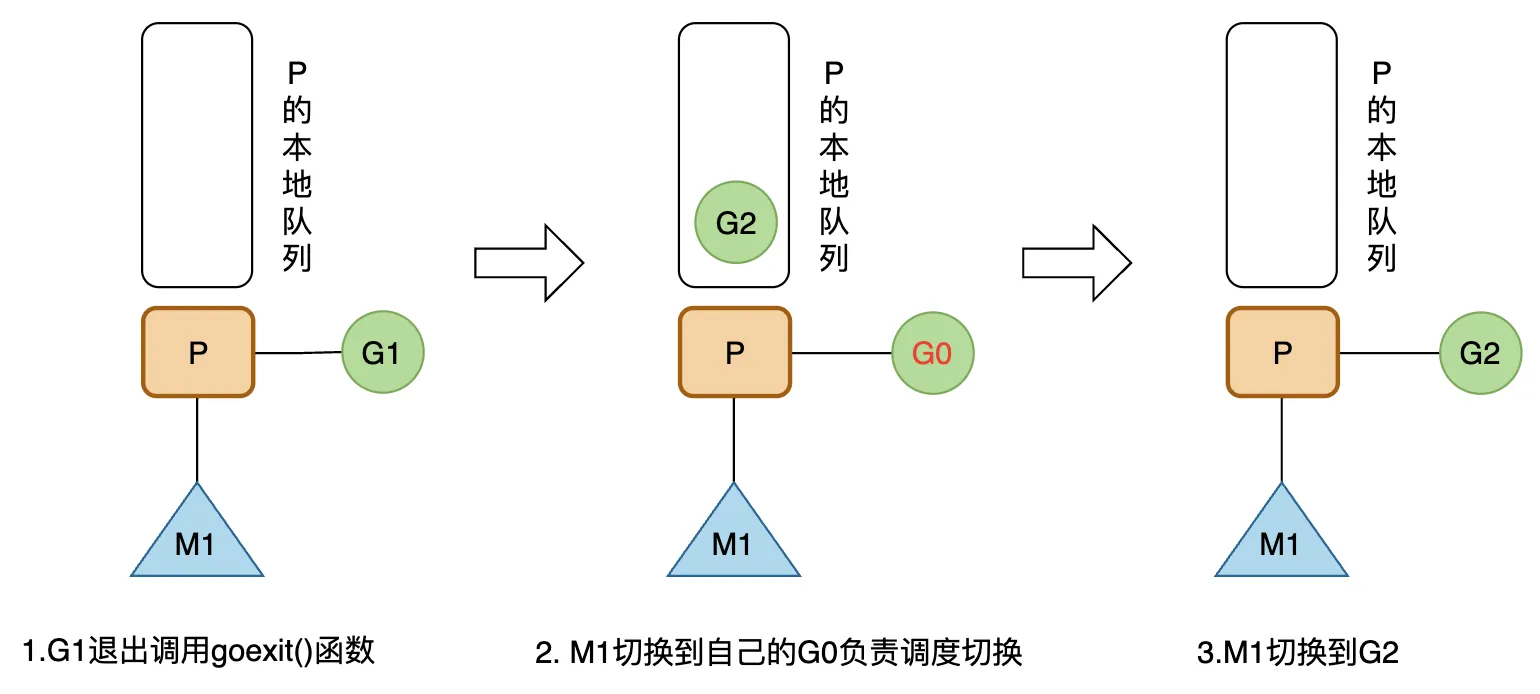
M1 上的 G1 运行完成后(调用 goexit() 函数),M1 上运行的 G 会切换为 G0,然后从 M1 绑定的 P 的本地队列中获取 G2 来执行。 G0 负责调度协调的切换(运行 schedule() 函数),是程序启动时,线程 M(也叫 M0)的系统栈表示的 G 结构体,负责 M 上 G 的调度。
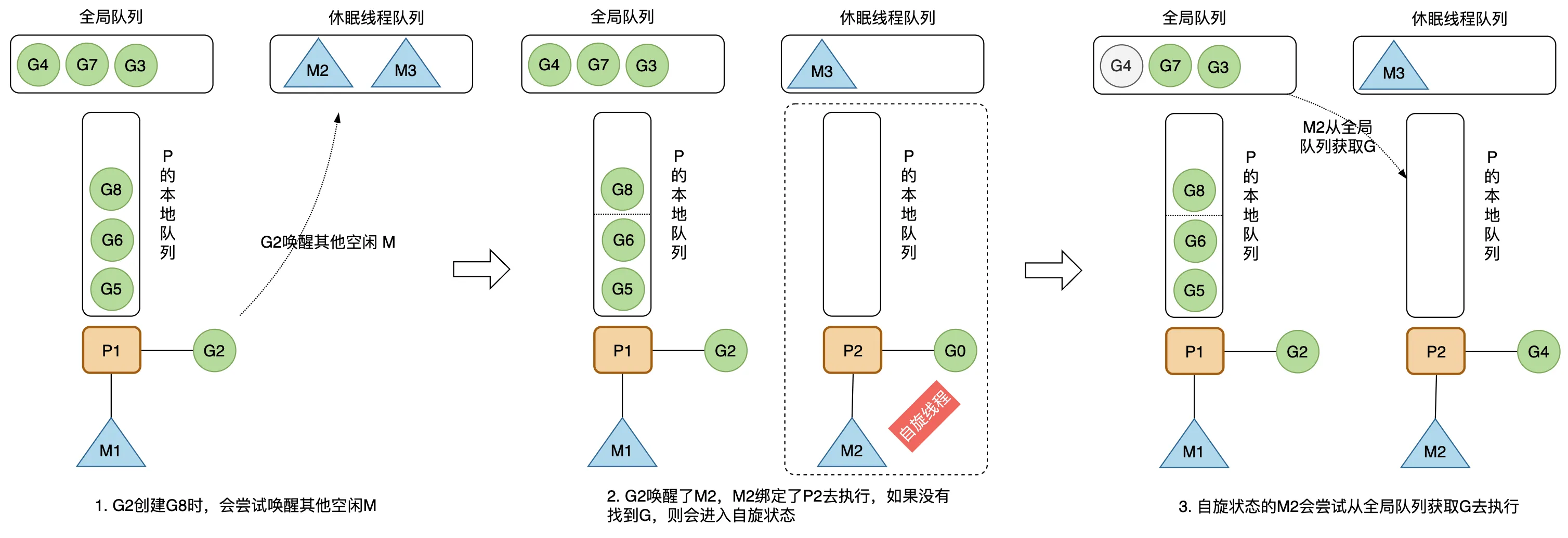
P 的本地队列最多能存 256 个 G,这里以最多能存 4 个为例说明。 正在 M1 上运行的 G2 要通过 go func() 创建 6 个 G。在前 4 个 G 放入 P 的本地队列中后,由于本地队列已满,创建第 5 个 G(G7)时,会将 P 的本地队列中前一半和 G7 一起打乱顺序放入全局队列中,P 的本地队列剩下的 G 则往前移动。然后创建第 6 个 G(G8),这时 P 的本地队列还未满,将 G8 放入本地队列中。
创建新的 G 时,运行的 G2 会尝试唤醒其它空闲的 M 绑定 P 去执行,如果 G2 唤醒了 M2,M2 绑定了一个 P2,会先运行 M2 的 G0。 这时候的 M2 没有从 P2 的本地队列中找到可用的 G,会进去自旋状态(spinning),处于自旋状态的 M2 会尝试从全局空闲线程队列里获取 G,放入 P2 的本地队列去执行。 获取的数量计算公式如下,每个 P 应该从全局队列承担一定数量的 G,但又不能太多,要给其他 P 留一些,提高并发执行的效率。 n = min(len(globrunqsize)/GOMAXPROCS + 1, len(localrunsize/2))
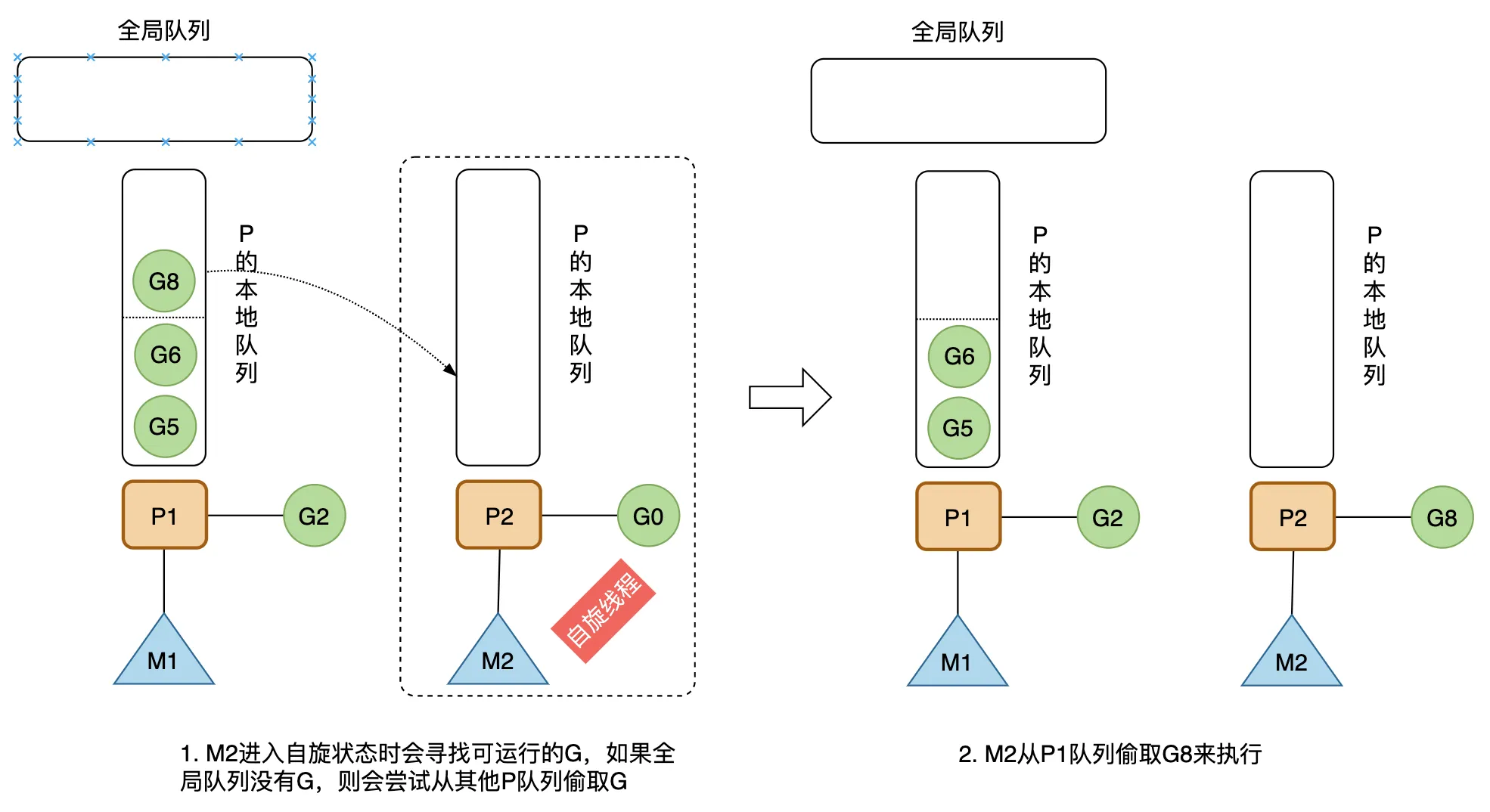
一个处于自旋状态的 M 会尝试先从全局队列寻找可运行的 G,如果全局队列为空,则会从其他 P 偷取一些 G 放到自己绑定的 P 的本地队列,数量是那个 P 运行队列的一半。
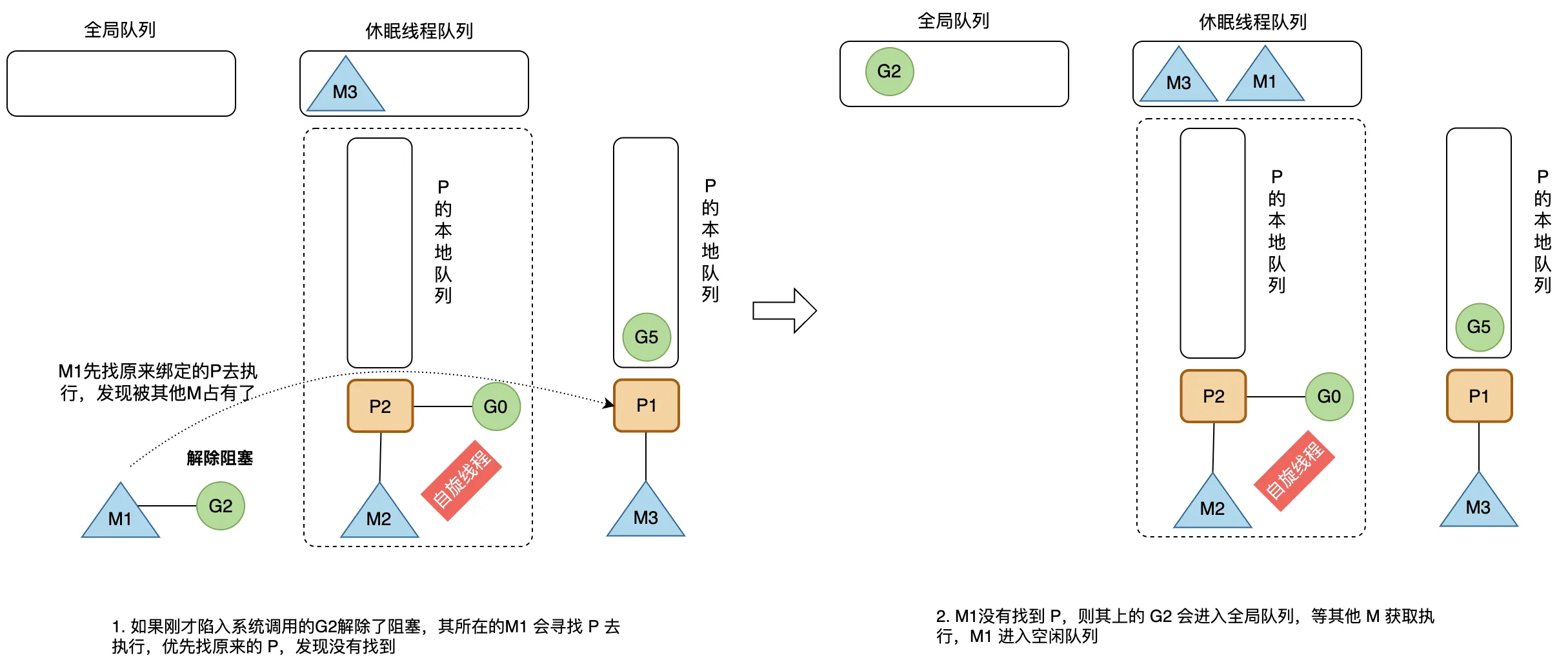
当 G2 发生系统调用进入阻塞,其所在的 M1 也会阻塞,进入内核状态等待系统资源。 为了提高并发运行效率,和 M1 绑定的 P1 会从休眠线程队列中寻找空闲的 M3 执行,以避免 P1 本地队列的 G 因为所在的 M1 进入阻塞状态而全部无法执行。 需要说明,如果 G 是进入通道阻塞,则该 M 不会一起进入阻塞,因为通道数据传输涉及内存拷贝,不涉及系统资源的等待。
当刚才进入系统调用的 G2 解除了阻塞,其所在的 M1 会重新寻找 P 去执行,优先会去找原来的 P。 如果找不到一个 P 进行绑定,则将解除阻塞的 G2 放入全局队列,等待其他的 P 获取和调度执行,然后将 M1 放回休眠线程队列中。
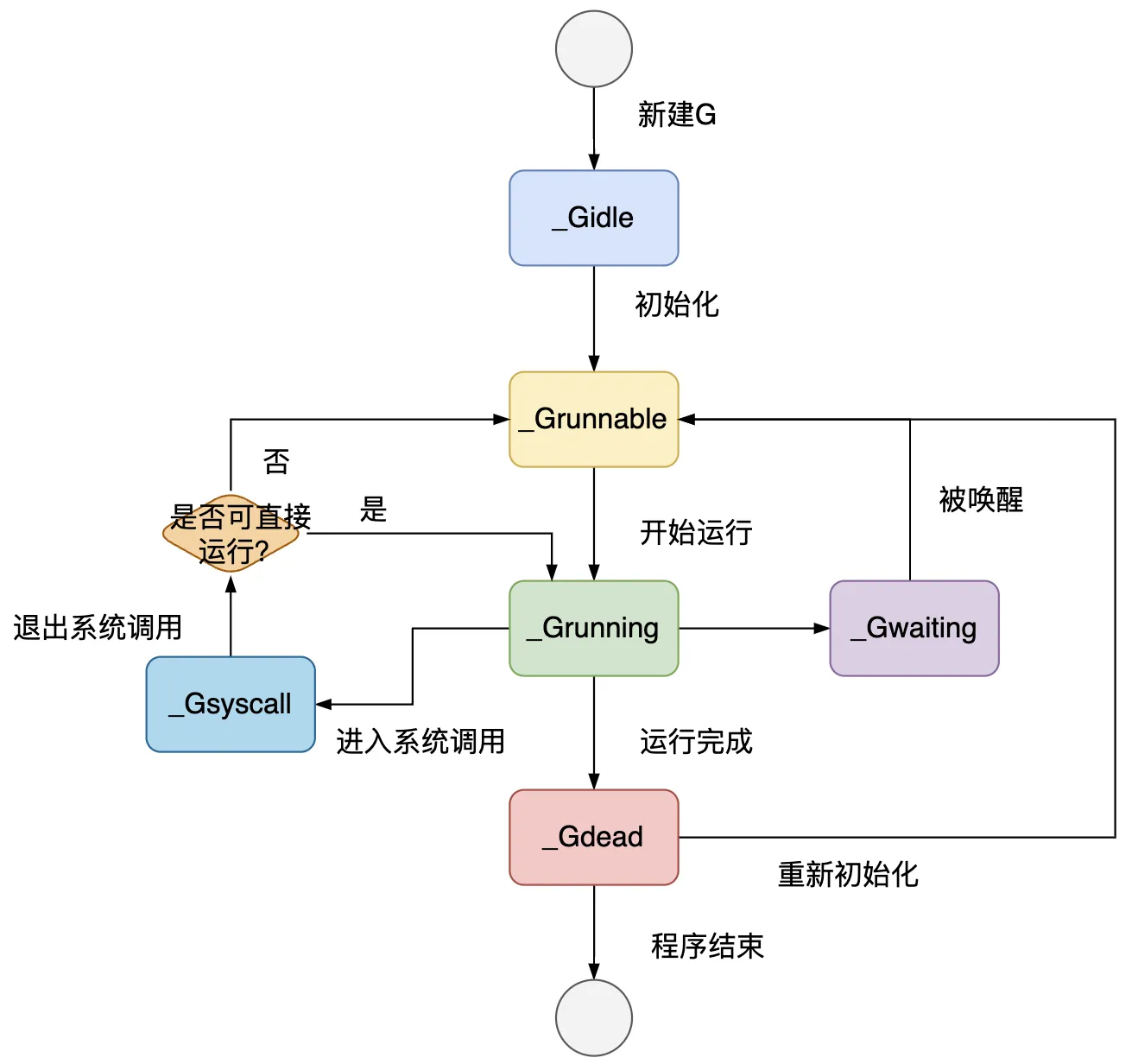
Go 的源码仓库地址:https://github.com/golang/go 4.1 数据结构与状态# 4.1.1 G#G 的数据结构定义在 Go 源码的 src/runtime/runtime2.go 中。 type g struct { stack stack // 描述了当前 Goroutine 的栈内存范围 [stack.lo, stack.hi) stackguard0 uintptr // 用于调度器抢占式调度 _panic *_panic // 最内侧的 panic 结构体 _defer *_defer // 最内侧的 defer 延迟函数结构体 m *m // 当前 G 占用的线程,可能为空 sched gobuf // 存储 G 的调度相关的数据 atomicstatus uint32 // G 的状态 goid int64 // G 的 ID waitreason waitReason // 当状态status==Gwaiting时等待的原因 preempt bool // 抢占信号 preemptStop bool // 抢占时将状态修改成 `_Gpreempted` preemptShrink bool // 在同步安全点收缩栈 lockedm muintptr // G 被锁定只能在这个 m 上运行 waiting *sudog // 这个 g 当前正在阻塞的 sudog 结构体 ...... }主要字段如下: stack:描述了当前协程的栈内存范围 [stack.lo, stack.hi) stackguard0:用于调度器抢占式调度 _defer 和 _panic:记录这个协程最内侧的 panic 和 defer 结构体 m:记录当前 G 占用的线程 M,可能为空 sched:存储 G 的调度相关的数据 atomicstatus:表示 G 的状态 goid:表示 G 的 id,对开发者不可见sched 字段的结构体为 runtime.gobuf,会在调度器将当前 G 切换离开 M,以及将当前 G 进入 M 执行时用到,栈指针 sp 和程序计数器 pc 用于存放和恢复寄存器中的值,改变程序执行的指令。 type gobuf struct { sp uintptr // 栈指针 pc uintptr // 程序计数器,记录G要执行的下一条指令位置 g guintptr // 持有 runtime.gobuf 的 G ret uintptr // 系统调用的返回值 ...... }atomicstatus 字段储存当前 G 的状态,枚举如下: const ( // _Gidle 表示 G 刚刚被分配并且还没有被初始化 _Gidle = iota // 0 // _Grunnable 表示 G 没有执行代码,没有栈的所有权,存储在运行队列中 _Grunnable // 1 // _Grunning 可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P _Grunning // 2 // _Gsyscall 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 _Gsyscall // 3 // _Gwaiting 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 _Gwaiting // 4 // _Gdead 没有被使用,没有执行代码,可能有分配的栈 _Gdead // 6 // _Gcopystack 栈正在被拷贝,没有执行代码,不在运行队列上 _Gcopystack // 8 // _Gpreempted 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 _Gpreempted // 9 // _Gscan GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 _Gscan = 0x1000 ...... )主要状态有: _Gidle:G 被创建但还未完全被初始化 _Grunnable:当前 G 可运行,正在等待被运行,当程序中的 G 非常多时,每个 G 就会有更多时间处于当前状态 _Grunning:当前 G 正在某个 M 上运行 _Gsyscall:当前 G 正在执行系统调用 _Gwaiting:当前 G 正在因为某个原因而等待 _Gdead:当前 G 完成了运行G 从创建到结束的生命周期经历的状态变化如下图。
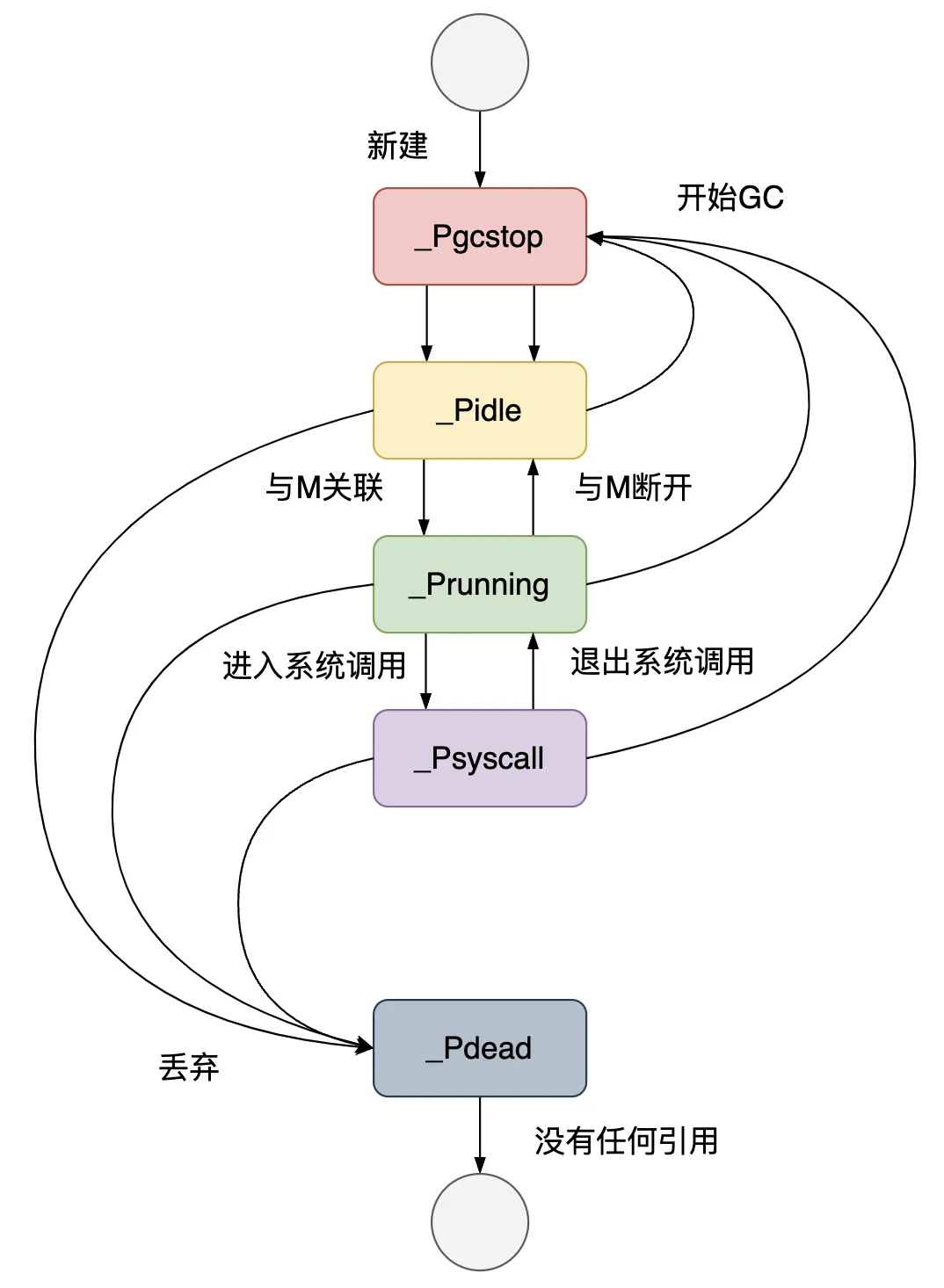
M 的数据结构定义在 Go 源码的 src/runtime/runtime2.go 中。 type m struct { g0 *g // 持有调度栈的 G gsignal *g // 处理 signal 的 g tls [tlsSlots]uintptr // 线程本地存储 mstartfn func() // M 的起始函数,go语句携带的那个函数 curg *g // 在当前线程上运行的 G p puintptr // 执行 go 代码时持有的 p (如果没有执行则为 nil) nextp puintptr // 用于暂存与当前 M 有潜在关联的 P oldp puintptr // 执行系统调用前绑定的 P spinning bool // 表示当前 M 是否正在寻找 G,在寻找过程中 M 处于自旋状态 lockedg guintptr // 表示与当前 M 锁定的那个 G ..... }主要字段如下: g0:在 Go 程序启动之初创建,用来调度其他 G 到 此 M 上 mstartfn:M 的起始函数,也就是使用 go 语句创建协程指定的函数 curg:存放当前正在运行的 G 的指针 p:指向当前和 M 绑定的 P nextp:暂存和 M 有潜在关联的 P spinning:当前 M 是否处于自旋状态,也就是处于寻找 G 的状态 lockedg:与当前 M 锁定的那个 G,当系统把一个 M 和一个 G 锁定,就只能双方相互作用,不再接受别的 GM 不存在记录状态的字段,M 的状态有以下几种: 自旋中:M 绑定了一个 P,且正在从运行队列获取 G 执行go代码中:M 绑定了一个 P,正在执行 go 代码 执行原生代码中:M 未绑定 P,正在执行原生代码或处于阻塞的系统调用 休眠中:M 未绑定 P,无待运行的 G,被添加到休眠线程队列 4.1.3 P#P 的数据结构定义在 Go 源码的 src/runtime/runtime2.go 中。 type p struct { status uint32 // p 的状态 pidle/prunning/... schedtick uint32 // 每次执行调度器调度 +1 syscalltick uint32 // 每次执行系统调用 +1 m muintptr // 关联的 m mcache *mcache // 用于 P 所在的线程 M 的内存分配的 mcache deferpool []*_defer // 本地 P 队列的 defer 结构体池 // 可运行的 G 队列,可无锁访问 runqhead uint32 runqtail uint32 runq [256]guintptr // 线程下一个需要执行的 G runnext guintptr // 空闲的 G 队列,G 状态 status 为 _Gdead,可重新初始化使用 gFree struct { gList n int32 } ...... }主要字段如下: status:P 的状态 runqhead、runqtail、runq:P 的本地队列,是一个长度为256的环形队列,储存着待执行的 G 的列表 runnext:线程下一个需要执行的 G gFree:P 的本地队列中状态为 _Gdead 的空闲的 G,可重新初始化使用status 字段的主要状态有: _Pidle:P 没有运行用户代码或者调度器,运行队列为空 _Prunning:和 M 绑定,正在执行用户代码或调度器 _Psyscall:M 陷入系统调用,没有执行用户代码 _Pgcstop:和 M 绑定,当前处理器由于垃圾回收被停止 _Pdead:当前 P 已经不被使用P 的各种状态转化关系如图:
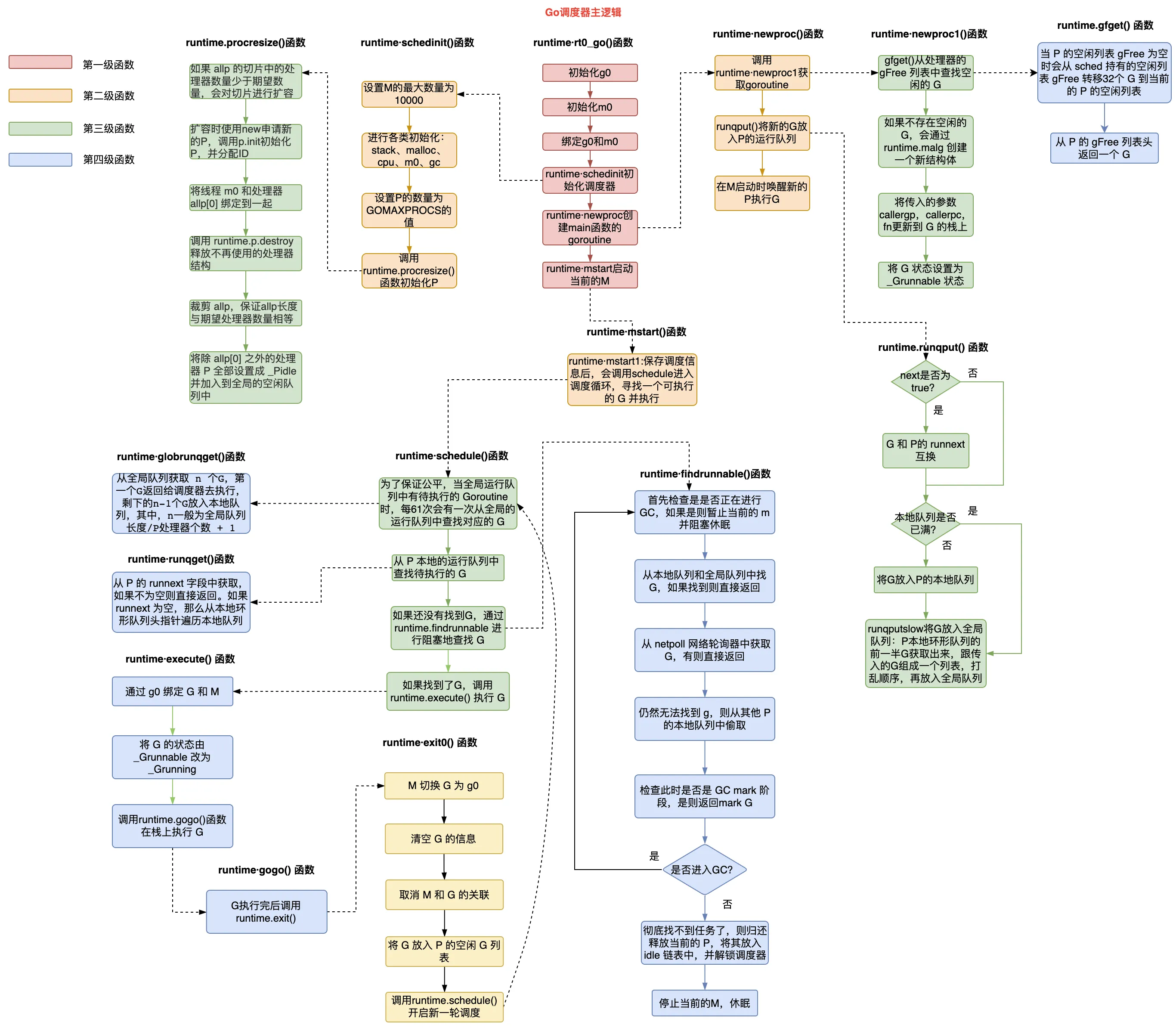
全局队列的数据结构为 schedt,以及一些全局变量。 // src/runtime/runtime2.go type schedt struct { lock mutex // schedt 的锁 midle muintptr // 空闲的 M 列表 nmidle int32 // 空闲的 M 列表的数量 nmidlelocked int32 // 被锁定正在工作的 M 数量 mnext int64 // 下一个被创建的 M 的 ID maxmcount int32 // 能拥有的最大数量的 M pidle puintptr // 空闲的 P 链表 npidle uint32 // 空闲 P 数量 nmspinning uint32 // 处于自旋状态的 M 的数量 // 全局可执行的 G 列表 runq gQueue runqsize int32 // 全局可执行 G 列表的大小 // 全局 _Gdead 状态的空闲 G 列表 gFree struct { lock mutex stack gList // Gs with stacks noStack gList // Gs without stacks n int32 } // sudog结构的集中存储 sudoglock mutex sudogcache *sudog // 有效的 defer 结构池 deferlock mutex deferpool *_defer ...... } var ( allm *m // 全局 M 列表 gomaxprocs int32 // P 的个数,默认为 ncpu 核数 ncpu int32 sched schedt // schedt 全局结构体 newprocs int32 allpLock mutex // 全局 P 队列的锁 allp []*p // 全局 P 队列,个数为 gomaxprocs ...... } // src/runtime/proc.go var ( m0 m // 进程启动后的初始线程 g0 g // 代表着初始线程的stack ) 4.2 启动函数#当 Go 程序启动时,Go 运行时 runtime 自带的 scheduler 就会开始启动工作。 以一个简单的 Go 程序为例: package main import "fmt" func main() { fmt.Println("hello world") }Go 程序的启动函数在 src/runtime/asm_arm64.s 的 rt0_go() 函数。 TEXT runtime·rt0_go(SB),NOSPLIT|TOPFRAME,$0 // 初始化g0 MOVD $runtime·g0(SB), g // 初始化 m0 MOVD $runtime·m0(SB), R0 // 绑定 g0 和 m0 MOVD g, m_g0(R0) MOVD R0, g_m(g) // 调度器初始化 BL runtime·schedinit(SB) // 创建一个新的 goroutine 来启动程序 MOVD $runtime·mainPC(SB), R0 // main函数入口 // 负责根据主函数即 main 的入口地址创建可被运行时调度的执行单元goroutine BL runtime·newproc(SB) // 开始启动调度器的调度循环 BL runtime·mstart(SB) DATA runtime·mainPC+0(SB)/8,$runtime·main(SB) // main函数入口地址 GLOBL runtime·mainPC(SB),RODATA,$8该启动函数主要做了几件事: 初始化 g0 和 m0,并将二者互相绑定,m0 是程序启动后的初始线程,g0 是 m0 的系统栈代表的 G 结构体,负责其他 G 在 M 上的调度切换 schedinit:进行各种运行时组件初始化工作,包括调度器与内存分配器、回收器的初始化、初始化 P 列表 newproc:根据主函数即 main 的入口地址创建可被运行时调度的执行单元 mstar:开始启动调度器的调度循环Go 程序启动后的调度器主逻辑如下图所示:
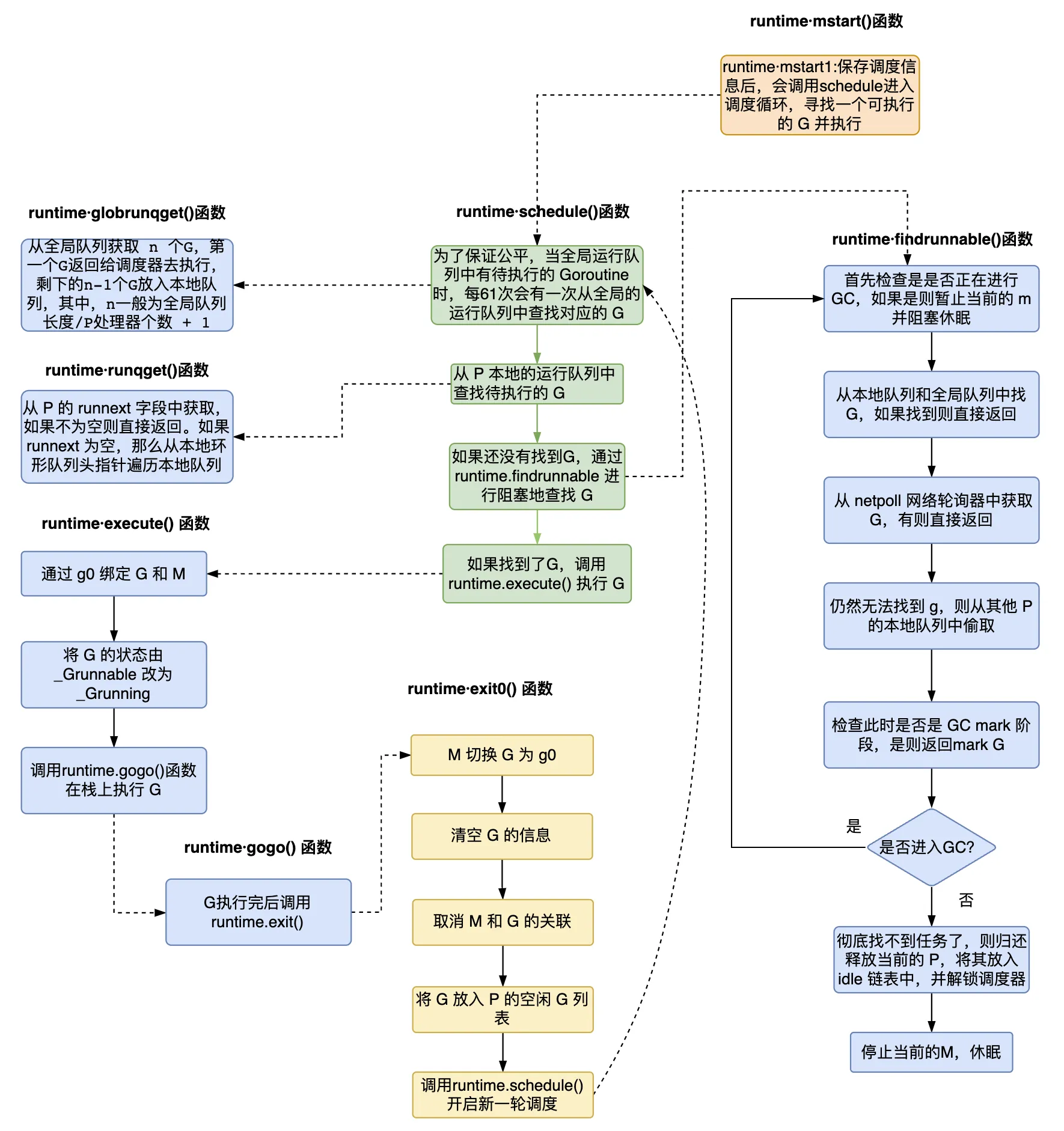
启动函数在初始化 g0 和 m0,并将它们绑定之后,就会调用调度器初始化函数 schedinit(),来初始化 allm 和 allp。 schedinit() 函数设置 M 的最大数量为 10000,实际中不会达到。然后分别调用 stackinit()、mallocinit()、mcommoninit()、gcinit() 函数执行栈初始化、内存分配器初始化、系统线程 M0 初始化、GC 垃圾回收器初始化。接着读取环境变量 GOMAXPROCS 并设置 P 的个数,然后调用 procresize() 函数初始化 P 列表。 // src/runtime/proc.go func schedinit() { // 获取当前的 G gp := getg() // 设置机器线程数M最大为10000 sched.maxmcount = 10000 // 栈、内存分配器初始化 stackinit() mallocinit() // 初始化系统线程 M0,加到 schedt 全局结构体中 mcommoninit(gp.m, -1) // GC初始化 gcinit() // 设置 P 的数量为 GOMAXPROCS procs := ncpu if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { procs = n } // 初始化 P 列表 if procresize(procs) != nil { throw("unknown runnable goroutine during bootstrap") } ...... }其中 mcommoninit() 函数负责初始化系统线程 M0,加到 schedt 全局结构体中。 // src/runtime/proc.go func mcommoninit(mp *m, id int64) { // id 传参 -1 // 获取当前的 G gp := getg() lock(&sched.lock) if id >= 0 { mp.id = id } else { mp.id = mReserveID() } ...... // 记录 allm 地址 mp.alllink = allm // allm = mp atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp)) unlock(&sched.lock) }procresize() 函数根据传入的 P 的数量来初始化 P 列表,allp 不足时进行扩容,并释放不会用到的 P。 // src/runtime/proc.go func procresize(nprocs int32) *p { // 之前的 P 数量 old := gomaxprocs if old < 0 || nprocs int32(len(allp)) { lock(&allpLock) if nprocs = 0; i-- { pp := allp[i] if gp.m.p.ptr() == pp { continue } pp.status = _Pidle // 将其他 P 状态设置为 _Pidle if runqempty(pp) { // 对于没有 G 本地队列的 P,放到全局空闲队列 pidleput(pp, now) } else { // 否则获取一个 M 并与 P 绑定 pp.m.set(mget()) pp.link.set(runnablePs) runnablePs = pp } } return runnablePs } 4.4 创建协程#在完成调度器的初始化之后,会调用 newproc() 函数来创建 G。 // src/runtime/proc.go func newproc(fn *funcval) { gp := getg() pc := getcallerpc() // 获取调用方 PC 寄存器值,即调用方程序要执行的下一个指令地址 systemstack(func() { // 用 g0 系统栈创建 G newg := newproc1(fn, gp, pc) // 调用 newproc1 获取 G 结构 pp := getg().m.p.ptr() runqput(pp, newg, true) // 将新创建的 G 放入 P 的本地队列 if mainStarted { // M 启动时唤醒新的 P 执行 G wakep() } }) }newproc() 函数调用 newproc1() 函数来获取新的 G 结构体。 // src/runtime/proc.go func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g { mp := acquirem() pp := mp.p.ptr() newg := gfget(pp) // 从 P 的空闲队列获取一个空闲的 G if newg == nil { // 获取不到则创建 newg = malg(stackMin) // 创建栈大小为 2KB 的 G casgstatus(newg, _Gidle, _Gdead) // 通过 CAS 的方式将 G 的状态变为 _Gdead allgadd(newg) // 将 _Gdead 状态的 g 添加到 allg,这样 GC 不会扫描未初始化的栈 } // 计算运行空间大小,对齐 totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) totalSize = alignUp(totalSize, sys.StackAlign) sp := newg.stack.hi - totalSize spArg := sp // 清理、创建并初始化 G 的运行现场 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) newg.sched.sp = sp newg.stktopsp = sp newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) newg.parentGoid = callergp.goid newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn // 将 G 的状态设置为_Grunnable casgstatus(newg, _Gdead, _Grunnable) // 生成唯一的goid newg.goid = pp.goidcache pp.goidcache++ // 释放对 M 加的锁 releasem(mp) return newg } 4.5 调度循环#在完成调度器的初始化,以及创建了 main 函数的 G 后,紧接着将会调用 runtime.mstart() 函数启动 M 去执行 G。 runtime.mstart() 函数将调用 mstart0() 函数,然后 mstart0() 函数再调用 mstart1() 函数。 // src/runtime/proc.go func mstart1() { gp := getg() if gp != gp.m.g0 { throw("bad runtime·mstart") } // 记录当前栈帧,便于其他调用复用,当进入 schedule 之后,再也不会回到 mstart1 gp.sched.g = guintptr(unsafe.Pointer(gp)) gp.sched.pc = getcallerpc() gp.sched.sp = getcallersp() asminit() minit() // 设置信号 handler;在 minit 之后,因为 minit 可以准备处理信号的的线程 if gp.m == &m0 { mstartm0() } // 执行启动函数 if fn := gp.m.mstartfn; fn != nil { fn() } // 如果当前 m 并非 m0,则要求绑定 p if gp.m != &m0 { acquirep(gp.m.nextp.ptr()) gp.m.nextp = 0 } // 开始调度循环,永不返回 schedule() }mstart1() 函数最后会调用 schedule() 函数,开始调度循环。 以下是 schedule() 函数的执行流程示意图。
schedule() 函数先阻塞等待找到一个可用的 G,然后执行这个 G,以此循环往复。 通过调用 findRunnable() 函数找到可用的 G,主要工作有: 检查是否在 GC,如果是则休眠当前 M 尝试从 P 的本地队列中取 G 返回 尝试从全局队列中取 G 返回 尝试从 netpoll 网络轮询器中获取 G 返回 尝试从其他 P 的本地队列偷取 G 返回 如果实在找不到可用的 G,则做一些额外的检查工作,将 P 放回空闲的 P 列表,停止当前 Mrunqget() 函数从本地队列获取 G,globrunqget() 函数从全局队列获取 G。 // src/runtime/proc.go func runqget(pp *p) (gp *g, inheritTime bool) { // 如果 runnext 不为空,直接获取返回 next := pp.runnext if next != 0 && pp.runnext.cas(next, 0) { return next.ptr(), true } // 从本地队列头指针遍历本地队列 for { h := atomic.LoadAcq(&pp.runqhead) t := pp.runqtail if t == h { // 本地队列为空 return nil, false } gp := pp.runq[h%uint32(len(pp.runq))].ptr() if atomic.CasRel(&pp.runqhead, h, h+1) { // cas-release, commits consume return gp, false } } } // src/runtime/proc.go func globrunqget(pp *p, max int32) *g { // 如果全局队列中没有 G 直接返回 if sched.runqsize == 0 { return nil } // 全局队列长度处以 P 的数量,避免拿太多 n := sched.runqsize/gomaxprocs + 1 if n > sched.runqsize { n = sched.runqsize } if max > 0 && n > max { n = max } if n > int32(len(pp.runq))/2 { n = int32(len(pp.runq)) / 2 } // 全局队列减去拿走的 G sched.runqsize -= n // 从全局队列取出一个 G 返回 gp := sched.runq.pop() n-- for ; n > 0; n-- { // 其余要从全局队列取出的 G 放入 P 的本地队列 gp1 := sched.runq.pop() runqput(pp, gp1, false) } return gp }然后调用 execute() 函数来执行 G,这里做的工作有: 给 G 的字段赋值,其中的状态是以 CAS 的方式进行修改的 调用 gogo() 函数执行 G,在其中执行完 G 后将调用 runtime.goexit() 退出,在结尾再次调用 runtime.schedule() ,进入下一次调度循环这里简单介绍一下 CAS(Compare And Swap),传入三个参数,分别是原有值、旧值和新值,Go 实现了判断一个值是否等于旧值,如果相等就将其赋值新值的原子操作。CAS 是一种无锁的方式,当多个线程尝试使用共享数据时,CAS能够检测到其他线程是否已经改变了这个数据。在 execute() 函数中,以 CAS 的方式修改 G 的状态,从 _Grunnable 改为 _Grunning,在一个循环中一直以 CAS 的方式判断,当状态是 _Grunnable 时则通过原子操作修改状态并返回,否则继续循环。 5. 参考# GitHub - golang/go: The Go programming language 深入分析Go1.18 GMP调度器底层原理-腾讯云开发者社区-腾讯云 详解Go语言调度循环源码实现 - luozhiyun`s Blog Golang的协程调度器原理及GMP设计思想 阐述一下Go中CAS算法 ?-帅地玩编程 |





【本文地址】
今日新闻 |
推荐新闻 |